在當今數據驅動決策的時代,一套系統化、可落地的數據治理體系已成為企業實現數據資產化、提升運營效率與智能化水平的核心基礎設施。它并非單一的技術項目,而是一個融合戰略、流程、技術與組織的系統工程,尤其圍繞數據倉庫、數據指標與數據處理服務三大支柱展開。以下將詳細闡述這一體系的建設方法論。
一、 核心理念與目標:從數據到價值
數據治理體系的根本目標是提升數據質量、保障數據安全、促進數據共享與應用,最終將原始數據轉化為可信、可用的業務洞察與決策依據。建設之初,必須明確與企業戰略對齊的業務目標,例如:提升報表準確性至99.5%、統一全公司客戶定義、支持實時業務監控等。
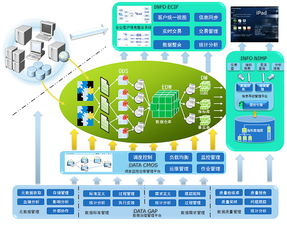
二、 核心支柱一:數據倉庫——治理的承載基石
數據倉庫是經過清洗、整合、建模的結構化數據存儲中心,是數據治理成果的物理體現。
- 分層架構設計:采用標準的ODS(操作數據存儲)、DWD(明細數據層)、DWS(匯總數據層)、ADS(應用數據層)模型。每一層都有明確的治理要求:ODS層保持原貌但統一接入;DWD層進行標準化、清洗、維度退化,形成企業一致的事實與維度;DWS層按主題域構建匯總模型;ADS層面向具體應用靈活構建。
- 數據模型治理:建立企業級統一的數據模型(如維度建模),定義核心業務實體(如客戶、產品、渠道)和一致性維度。這是確保數據口徑一致、減少數據冗余的關鍵。
- 元數據管理:建立技術元數據(表結構、ETL任務、血緣關系)和業務元數據(指標定義、業務術語)的集中管理。數據血緣追蹤能快速定位問題影響,業務術語表能統一溝通語言。
三、 核心支柱二:數據指標——治理的價值標尺
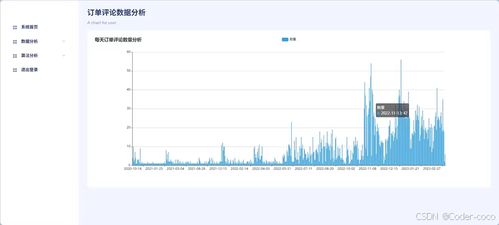
數據指標是業務效能的可量化度量,是數據價值輸出的直接載體。指標體系的混亂是常見痛點。
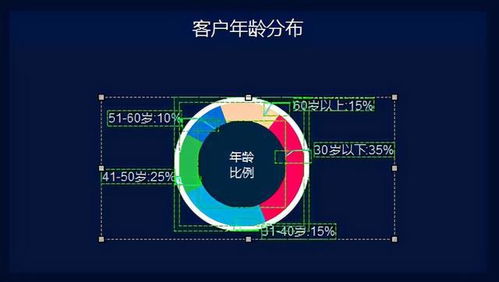
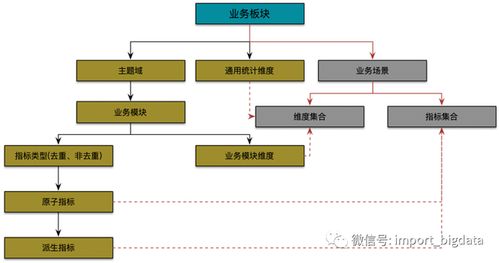
- 指標規范化定義:遵循“業務域-主題域-業務過程-指標”的層級劃分。每個指標必須擁有唯一的、權威的編碼,并明確其業務定義、統計口徑(分子/分母/過濾條件)、計算邏輯、數據來源、更新頻率、責任部門。例如,“日活躍用戶數(DAU)”需明確是登錄用戶還是訪問用戶,去重規則是什么。
- 指標分級分類管理:將指標分為原子指標(基礎度量,如“交易金額”)、派生指標(由原子指標疊加維度、統計周期構成,如“過去7天各省份日均交易金額”)和復合指標(由多個指標計算得出,如“毛利率”)。建立企業指標庫,實現指標的共享與復用。
- 指標生命周期管理:涵蓋指標的申請、評審、開發、發布、變更、下線全流程,確保指標的嚴謹性和可持續性。
四、 核心支柱三:數據處理服務——治理的流程引擎
數據處理服務負責將原始數據加工成倉庫中的模型和可用的指標,是治理規則落地的執行者。
- 標準化開發流程與規范:制定從數據探查、需求分析、模型設計、代碼開發(SQL/腳本規范)、測試驗證到任務上線和運維監控的全流程規范。強調代碼可讀性、可維護性和任務健壯性。
- 任務調度與依賴管理:使用成熟的調度工具(如Airflow、DolphinScheduler)管理復雜的ETL/ELT任務流,清晰定義任務間的依賴關系,確保數據處理的有序和高效。
- 數據質量監控閉環:在關鍵處理節點嵌入數據質量校驗規則(如唯一性、非空、值域、波動性檢查)。一旦觸發告警,能通過血緣關系快速定位問題源頭,并流轉至工單系統進行修復,形成“監控-發現-定位-修復-驗證”的閉環。
- 性能與成本優化:持續監控任務運行時長和資源消耗,對熱點數據、低效SQL、小文件等問題進行優化,平衡處理效率與計算成本。
五、 體系建設方法論:四步走實施路徑
- 組織與評估先行:成立由業務、數據、技術部門代表組成的數據治理委員會,明確職責。對現有數據資產、數據質量、管理流程進行全面評估,識別關鍵痛點與優先級。
- 規劃與設計藍圖:制定符合企業現狀的治理愿景、目標和實施路線圖。重點設計數據倉庫分層模型、核心主題域、關鍵指標體系框架以及數據處理技術棧選型。
- 試點與敏捷迭代:選擇1-2個業務價值高、范圍可控的領域(如“營銷效果分析”)作為試點。在該領域內,完整實踐從模型設計、指標定義、開發處理到應用落地的全過程,打通閉環,積累經驗并完善治理流程與工具。
- 推廣與持續運營:將試點成功的模式、規范和工具推廣到其他業務域。將數據治理工作常態化、制度化,通過定期的質量評估、指標審計、元數據維護和培訓宣導,確保體系持續有效運轉,并隨業務發展而演進。
###
數據倉庫、數據指標與數據處理服務,三者相輔相成,共同構成了數據治理體系的“鐵三角”。倉庫提供標準化“原料”,指標定義價值“標尺”,處理服務則是高效“生產線”。成功的體系建設必須堅持“業務驅動、技術支撐、流程保障、組織協同”的原則,以終為始,通過迭代漸進的方式,最終建立起一個透明、可信、高效的數據環境,讓數據真正成為企業的核心資產與競爭力源泉。